Raft
针对Multi Poxos的提出工程化改进,并提供工程化实现。
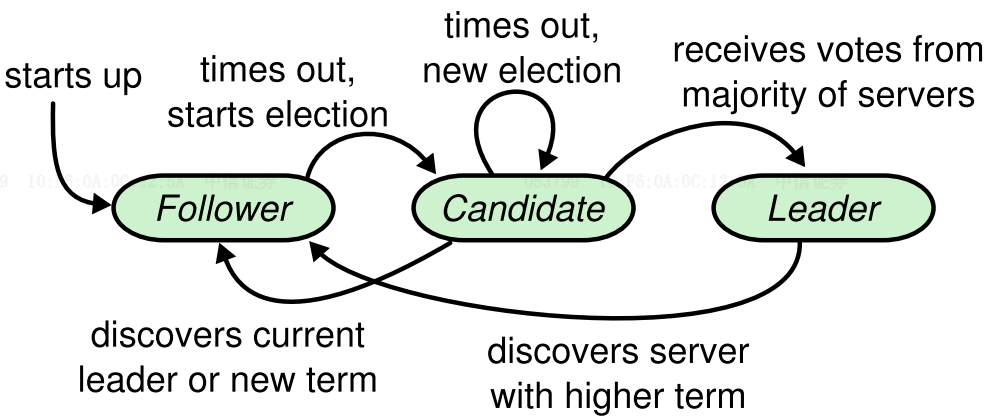
成员
leader主节点,负责接受与响应用户请求,并向从节点发送日志记录,以及收集从节点反馈。follower从节点,负责响应leader日志复制和condidate竞选主节点请求。condidate候选人节点,竞选leader时的临时状态,竞选成功后成为leader,失败后成为follower。
选举
节点间通过RPC通信,
AppendEntries RPC用于日志同步、RequestVote RPC用于主节点选举,心跳信号为内容为空的AppendEntries RPC。每个节点都有单调递增的任期编号
curr_term,视为逻辑时钟,用于检测过期信息,并定期与其它节点交换任期信息,当发现更高任期的节点(当前节点选举失败、所在分区被合并),则将自己任期更新,并成为follower节点。
流程
主节点定时广播心跳信号,宣誓主权。
1// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #tickHeartbeat2// 定时心跳宣示主权3func (r *raft) tickHeartbeat() {4// 递增心跳计数器5r.heartbeatElapsed++6// 满足发送心跳时间间隔7if r.heartbeatElapsed >= r.heartbeatTimeout {8r.heartbeatElapsed = 09if err := r.Step(pb.Message{From: r.id, Type: pb.MsgBeat}); err != nil {10}11}12}
当
follower在超时后未收到主节点心跳信号,将成为pre_condidate,如果节点日志不落后于过半节点(通过投票实现,预选举可以投出多票),将成为condidate,之后为自己投一票,并将curr_term +=1,向其它节点发送RequestVote请求。etcd引入预选举机制,如果节点日志不落后于过半节点,才有可能成为新主节点,否则将放弃竞选,减少无效选举次数。x1// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #tickElection2// 超时触发选举/预选举流程3func (r *raft) tickElection() {4r.electionElapsed++5// 可以被提升为leader && 候选等待超时6if r.promotable() && r.pastElectionTimeout() {7r.electionElapsed = 08if err := r.Step(pb.Message{From: r.id, Type: pb.MsgHup}); err != nil {9}10}11}1213// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #campaign14// 开始选举/预选举15func (r *raft) campaign(t CampaignType) {16// etcd引入预选举,如果节点日志不落后于过半节点,才有可能成为新主节点,17// 否则将放弃竞选,减少无效选举次数18if t == campaignPreElection {19r.becomePreCandidate()20voteMsg = pb.MsgPreVote21term = r.Term + 122} else {23// 切换到Candidate状态,term已在预先选举中递增24r.becomeCandidate()25voteMsg = pb.MsgVote26term = r.Term27}28// 向集群中的所有节点发送信息,请求投票29for _, id := range ids {30if id == r.id {31// 候选人为自己投一票32r.send(pb.Message{To: id, Term: term, Type: voteRespMsgType(voteMsg)})33continue34}35// 向集群中的其它节点发送投票请求36r.send(pb.Message{To: id, Term: term, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})37}38}其余节点处,如果
pre_condidate/condidate的日志不落后于当前节点(condi.LogTerm > MyTerm || (condi.LogTerm == MyTerm && condi.Index >= MyIndex)),将响应RequestVote请求成功信号,否则响应失败信号,节点在一个任期内,只有一次正式选举投票机会,但有多次预选举投票机会。
xxxxxxxxxx251// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #Step2// 节点响应预选举/选举拉票请求3func (r *raft) Step(m pb.Message) error {4 case pb.MsgVote, pb.MsgPreVote:5 // 已为m.From节点投过票 6 canVote := r.Vote == m.From ||7 // 当前未投过票并且集群中无主节点8 (r.Vote == None && r.lead == None) ||9 // pre_condidate任期高于自己10 (m.Type == pb.MsgPreVote && m.Term > r.Term)11 12 // 当前节点可以投票 && m.From节点的termId,logindex不落后当前节点13 // isUpToDate: m.LogTerm > MyTerm || (m.LogTerm == MyTerm && m.Index >= MyIndex)14 if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {15 // m.From数据不落后于当前节点,投赞成票16 r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)})17 // 预投票不产生真正主节点,不消耗票数,可以投多票18 if m.Type == pb.MsgVote {19 r.Vote = m.From20 }21 } else {22 // m.From数据落后于当前节点,投反对票23 r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})24 }25}
获得过半票的
pre_condidate将成为condidate,开始真正的竞选。获得过半票的condidate将成为condidate,成功后成为新的leader,并广播心跳,宣示主权,其余condidate将收到新leader的心跳信号,转变为follower。xxxxxxxxxx201// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #stepCandidate2// 响应投票结果3func stepCandidate(r *raft, m pb.Message) error {4gr, rj, res := r.poll(m.From, m.Type, !m.Reject)5switch res {6// 赢得投票7case quorum.VoteWon:8// 如果赢得的是预选举,将进入真正的选举9if r.state == StatePreCandidate {10r.campaign(campaignElection)11} else {12// 赢得真正的选举,成为主节点,广播心跳宣示主权13r.becomeLeader()14r.bcastAppend()15}16case quorum.VoteLost:17// 输掉预选举、或者真正选举,变回从节点18r.becomeFollower(r.Term, None)19}20}为避免多节点同时成为
pre_condate,并在预选举成功后成为condate,导致分票,选举失败,Raft为每个节点设置随机的主节点心跳检测超时时间[Timeout, 2*Timeout)。xxxxxxxxxx41// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go2func (r *raft) resetRandomizedElectionTimeout() {3r.randomizedElectionTimeout = r.electionTimeout + globalRand.Intn(r.electionTimeout)4}
安全性
利用
log的连续无空洞特性,某个entry被确认,则之前的entry都被确认。如果某个entry被确认写入大部分从节点,则保证过半从节点与主节点保持一致;follower只为最新数据不晚于自己的condidate投票,保证只有和主节点拥有相同数据的condidae才能成为leader,避免leader从follower同步数据;xxxxxxxxxx61if my_termid > condi_termid:2return refuse3elif my_termid == condi_termid and my_logindex > condi_logindex:4return refuse5else:6return accept
log复制
日志log中每个
entry包含提交该entry的任期、在log中下标和命令内容<termId, logindex, cmd>。xxxxxxxxxx61// etcd#raft.pb.go#Entry2type Entry struct {3Term uint644Index uint645Data []byte6}每个节点包含以下数据:
curr_termid当前任期、log[]日志、commitInexlog中已提交entry最大下标;主节点在此基础上,还拥有
nextindex[]表示每个follower里面下一次应该写入的下标(类似TCP中的ack)。Message是消息的抽象,用于各个节点间通讯,包含各种消息所需要的字段:当前任期、待发送的多个日志信息、前,xxxxxxxxxx101// etcd#raft.pb.go#Message2type Message struct {3Term uint644// 第一条Entry的Term值5LogTerm uint646// 第一条Entry的logindex-17Index uint648// 需要存储的日志信息9Entries []Entry10}
流程
(0)-> 新写入操作到来,设置
entry的termid, logindex,并将entey写入主节点log,该entry状态记为uncommited,最后广播日志消息;xxxxxxxxxx291// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #stepLeader2// 主节点写入日志,并广播日志3func stepLeader(r *raft, m pb.Message) error {4switch m.Type {5case pb.MsgProp:6// 主节点写入日志7if !r.appendEntry(m.Entries...) {8return ErrProposalDropped9}10// 向从节点广播日志11r.bcastAppend()12return nil13}14}1516// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #appendEntry17// 主节点设置消息的termid, logindex后写入自身log18func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {19li := r.raftLog.lastIndex()20// 设置termid, 与递增logindex21for i := range es {22es[i].Term = r.Term23es[i].Index = li + 1 + uint64(i)24}25// 写入主节点log26li = r.raftLog.append(es...)27r.send(pb.Message{To: r.id, Type: pb.MsgAppResp, Index: li})28return true29}(1)->主节点向从节点发送
AppendEntries请求,携带当前任期、log中nextindex[i]~logindex之间entry内容,以及第nextindex[i]个entry的前一个entry的下标和任期:<termid, enties, prev_logindex, prev_termid>xxxxxxxxxx331// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #bcastAppend2// 向除自身外节点广播日志消息3func (r *raft) bcastAppend() {4r.trk.Visit(func(id uint64, _ *tracker.Progress) {5if id == r.id {6return7}8r.sendAppend(id)9})10}1112// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #maybeSendAppend13// 主节点构造需要发生的数据14func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {15pr := r.trk.Progress[to]16// pr.Next表示follower的日志中下一次应该写入的下标(类似TCP中的ack)17// 当前消息应该从followerlog的pr.Next处开始写入18// pr.Next-1表示follower的日志中,开始写入位置前一个entey下标19lastIndex, nextIndex := pr.Next-1, pr.Next20// lastTerm表示follower开始写入位置前一个entey里面的任期21// (lastTerm,lastIndex)将用于确认新写入日志能与原有日志拼接出完整日志22lastTerm, errt := r.raftLog.term(lastIndex)2324var ents []pb.Entry25var erre error26// 发送消息包含log中nextindex到logindex之间entry内容,27if pr.State != tracker.StateReplicate || !pr.Inflights.Full() {28ents, erre = r.raftLog.entries(nextIndex, r.maxMsgSize)29}30if err := pr.UpdateOnEntriesSend(len(ents), uint64(payloadsSize(ents)), nextIndex); err != nil {31r.logger.Panicf("%x: %v", r.id, err)32}33}(2)->从节点收到消息后,通过检查本地日志中是否存在
lastIndex对应的节点,判断收到的日志能否写入,并且不会造成空洞。如果lastIndex对应节点存在,则找到新收到日志中entries[lastIndex:]与本地日志log[lastIndex:]不匹配的第一个节点x,本地日志log[lastIndex+1:x-1]与要添加日志entries[0:x-lastIndex-2]之间一致,不用覆盖,只需要将entries[x-lastIndex-1:]追加到本地日志末尾,之后更新commitIndex,并返回匹配,主节点更新nextindex[i];如果不存在则返回不匹配;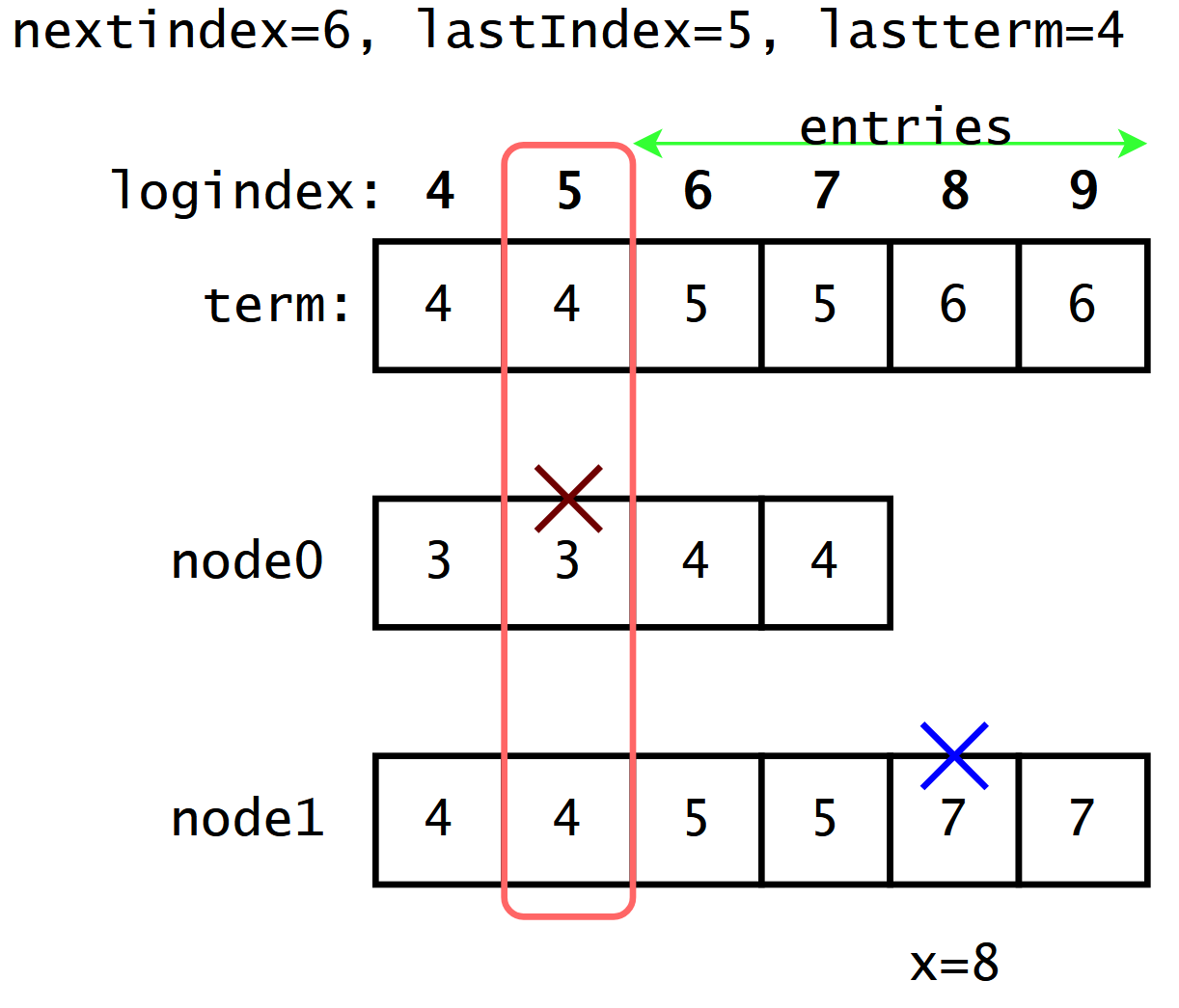
以上图为例:主节点将
log[6:9]处日志复制给从节点,此时lastIndex=5, lastterm=4。从节点node0处不存在logindex=5, term=4的节点,无法将log[6:9]复制到本地,同时不产生空洞;从节点node1处存在logindex=5, term=4的节点,可以进行复制,然后找到主节点log[6:9]与本地log[6:]之间第一个差异点的的下标x=8,最后将主节点的log[8:9]覆盖到从节点log[8:]。xxxxxxxxxx571// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #stepFollower2// 从节点收到消息后尝试写入log3func stepFollower(r *raft, m pb.Message) error {4switch m.Type {5case pb.MsgApp:6r.electionElapsed = 07r.lead = m.From8r.handleAppendEntries(m)9return nil10}1112// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #handleAppendEntries13// 从节点判断接收到entry能否加到自身log中,获得完整准确的log14func (r *raft) handleAppendEntries(m pb.Message) {15// 请求的日志索引小于follower已提交的日志索引,不需要重复写入16if m.Index < r.raftLog.committed {17r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})18return19}20// 尝试将leader的日志追加到自己的日志中21if mlastIndex, ok := r.raftLog.maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries...); ok {22r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})23return24}25// 不能追加到消息尾部,需要找到主从节点的公共log节点x,26// 之后主节点发送log[x:]到从节点,从节点从x处开始覆盖本地log27hintIndex := min(m.Index, r.raftLog.lastIndex())28hintIndex, hintTerm := r.raftLog.findConflictByTerm(hintIndex, m.LogTerm)29r.send(pb.Message{30To: m.From,31Type: pb.MsgAppResp,32Index: m.Index,33Reject: true,34RejectHint: hintIndex,35LogTerm: hintTerm,36})37}3839// https://github.com/etcd-io/raft/blob/v3.6.0-alpha.0/raft.go #maybeAppend40// 尝试将日志追加到当前日志末尾41func (l *raftLog) maybeAppend(index, logTerm, committed uint64, ents ...pb.Entry) (lastnewi uint64, ok bool) {42// index: ents中第一个entry的下标-143// 如果现有日志和要追加的日志无交集,无法添加到现有日志末尾44if !l.matchTerm(index, logTerm) {45return 0, false46}47lastnewi = index + uint64(len(ents))48// 找到现有日志和要添加日志之间第一个冲突点下标ci49// 本地日志log[index+1:ci-1]与要添加日志ents[0:ci-index-2]之间一致,不用覆盖50// 将ents[ci-index-1]添加到log末尾即可51ci := l.findConflict(ents)52offset := index + 153l.append(ents[ci-offset:]...)54// 提交新写入日志55l.commitTo(min(committed, lastnewi))56return lastnewi, true57}(3)->如果消息中entries不能直接添加到本地Log末尾,说明entries与本地log无公共节点,将不断尝试
nextindex[i]-=1,以回溯找寻公共节点,反馈后将发送新一轮的nextindex[i]~logindex之间entry,重试步骤(1), (2), (3),直至返回匹配;xxxxxxxxxx121// 尝试找到本地log与消息中entries的公共节点2func (l *raftLog) findConflictByTerm(index uint64, term uint64) (uint64, uint64) {3// 向前找到一个小于或等于leader日志任期的日志索引4for ; index > 0; index-- {5if ourTerm, err := l.term(index); err != nil {6return index, 07} else if ourTerm <= term {8return index, ourTerm9}10}11return 0, 012}(4)->主节点收到过半从节点写入成功,该
entry状态记为commited,向客户返回成功;
xxxxxxxxxx61func (r *raft) maybeCommit() bool {2 // 获得已保存到过半节点的日志的最大索引3 mci := r.trk.Committed()4 // 提交该索引5 return r.raftLog.maybeCommit(mci, r.Term)6}安全性保障
保证主从log中具有相同
termId, logindex的entry的cmd相同;保证主从log中,如果两边存在某个
entry的termId, logindex匹配,则该entey之前的entry都匹配;所有节点都会拥有一致的状态机输入序列,各个节点通过一致的初始状态 + 一致的状态机输入序列得到一致的最终状态。
遗留数据处理
当新主节点选举后,主节点可能包含未满足过半从节点确认,未提交的日志。新主节点首先将该部分日期复制到过半从节点,但是并不提交。而是当有新消息到来后,通过提前当前日志的方式,利用log连续无空洞特性,之前复制的遗留日志将一并被提交。
为什么不能主动提交遗留日志:假设主节点
A上有遗留日志m0,节点B有其他遗留日志m1:A(m0), B(m1), C()。如果复制m0时未覆盖节点B上的m1,得到A(m0), B(m1), C(m0),然后提交m0。当节点B选举成为主节点后,复制m1时覆盖了A上的m0:A(m1), B(m1), C(m1)导致提交后的日志m0丢失。如果不主动提交遗留日志,在节点
A成为主节点,复制mo,B成为主节点,复制消息m1后,A(m1), B(m1), C(m1)。复制来到消息后:A(m1,m2), B(m1,m2), C(m1,m2),然后主动提交m2,m1被附带确认,此时消息m0丢失,但系统保持状态一致。
Log瘦身
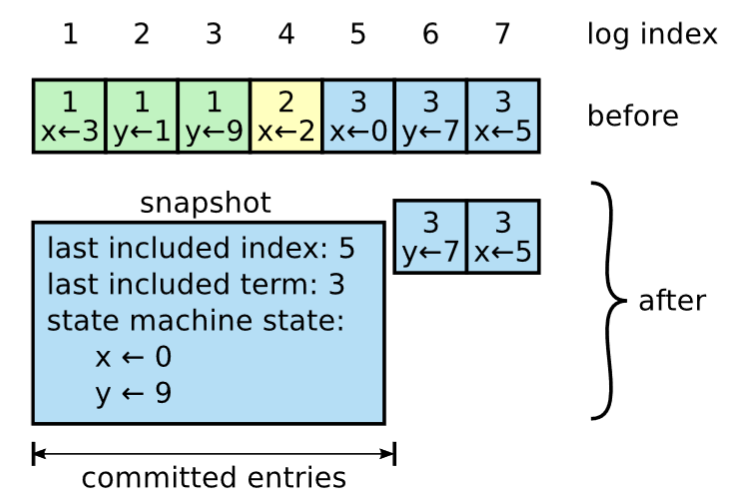
Raft通过建立快照,保存当前时刻状态机(变量)的最终值,类似于Redis追加日志的整理,实现历史数据清理。
最终一致性
raft无法保证实时主从一致性,只能保证最终一致性。通过限制只能从主节点读取,保证一致的最新的数据视图。
通过主节点的心跳信号(心跳信号处理简单,但是会瞬时增大硬件资源开销),或者手动发送空白
appendEntries(日志复制处理复杂,实质上属于背压机制,控制了并发度),如果收到过半从节点响应,证明当前节点是主节点,可以从当前节点读取值,并返回。如果不能保证当前节点是主节点,将读取请求转发到主节点。
multi Pasox与Raft
相同点
从所有节点中选出主节点,接受所有的写操作,并将日志发送给从节点;
过半节点复制日志后,该日志即可提交,所有节点将该日志中的命令应用于他们的状态机;
如果主节点宕机,通过过半选举的方式选出一个新的主节点;
满足状态机安全性:节点间如果
entry的任期和下标相同,则该entry完全一致;满足领导完整性:后续主节点将继承之前主节点提交日志,不做修改。
不同点
Raft算法给出了大量的实现细节(如何选举主节点、如何保证主从日志一致、如何为日志瘦身);Raft写日志操作必须是串行的,只有前一个请求完成后,才能处理下一个请求;Multi-Paxos可以并发修改日志,允许日志不按顺序提交,如果当前请求未能抢占到锁,将帮助之前获得锁请求完成日志复制;Raft利用log完整无空洞的特性,保证过半从节点数据完整,新选举的leader数据也是完整的,保证日志只能从leader流向follower;Multi-Paxo复制请求顺序是随机的,日志存在空洞,新leader产生后,需要重新对每个未提交的日志进行确认,向其它从节点学习缺失,但是可以被提交的日志,优点是写入并发性能提高,提高吞吐量。