文件上传
FastDFS
1,开源的轻量级分布式文件系统,通过集群扩展用于解决大数据量存储和负载均衡等问题。支持HTTP协议传输文件(结合Nginx);对文件内容做Hash处理,节约磁盘空间;通过Nginx多tracker、多group、group下多存储主机实现负载均衡,整体性能较佳。适用中小型系统。
2,FastDFS的二个角色:跟踪服务器(Tracker)、存储服务器(Storage)。跟踪服务器:主要做调度工作,起到负载均衡的作用。它是客户端和存储服务器交互的枢纽,将数据请求落到某个group上。存储服务器:主要提供容量和备份服务,存储服务器是以组(Group)为单位,每个组内可以有多台存储服务器,数据互为备份。文件及属性(Meta Data)都保存在该服务器上。
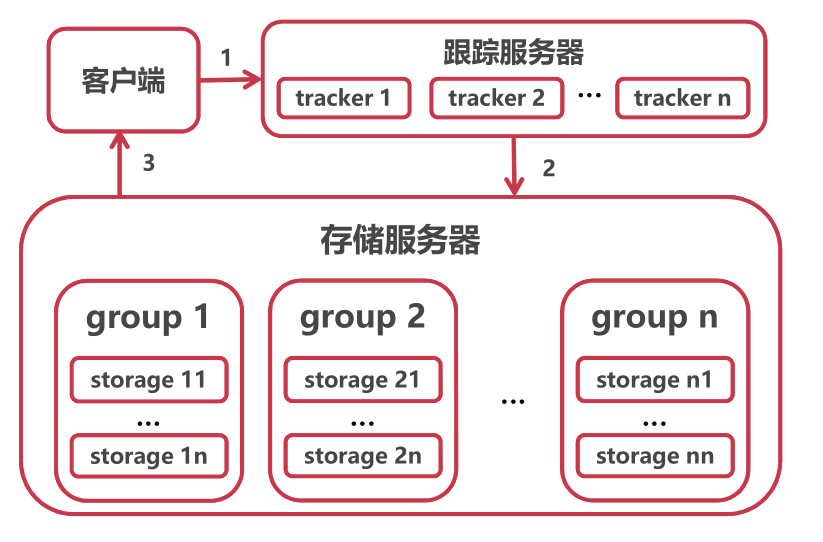
3,安装
x
1# 环境2yum install git gcc gcc-c++ make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim -y3
4# 保存目录5mkdir /home/dfs #创建数据存储目录6cd /usr/local/src #切换到安装目录准备下载安装包7
8# 安装libfastcommon9git clone https://github.com/happyfish100/libfastcommon.git --depth 110cd libfastcommon/11./make.sh && ./make.sh install #编译安装12
13# 安装FastDFS14cd ../ #返回上一级目录15git clone https://github.com/happyfish100/fastdfs.git --depth 116cd fastdfs/17./make.sh && ./make.sh install #编译安装18#fastdfs配置文件准备,新版本下tracker.conf,storage.conf,client.conf已经存在不用再次复制19cp /etc/fdfs/tracker.conf.sample /etc/fdfs/tracker.conf20cp /etc/fdfs/storage.conf.sample /etc/fdfs/storage.conf21cp /etc/fdfs/client.conf.sample /etc/fdfs/client.conf #客户端文件,测试用22#nginx相关配置文件准备23cp /usr/local/src/fastdfs/conf/http.conf /etc/fdfs/ #供nginx访问使用24cp /usr/local/src/fastdfs/conf/mime.types /etc/fdfs/ #供nginx访问使用25
26# 安装fastdfs-nginx-module27cd ../ #返回上一级目录28git clone https://github.com/happyfish100/fastdfs-nginx-module.git --depth 129cp /usr/local/src/fastdfs-nginx-module/src/mod_fastdfs.conf /etc/fdfs30
31# 安装nginx32wget http://nginx.org/download/nginx-1.15.4.tar.gz #下载nginx压缩包33tar -zxvf nginx-1.15.4.tar.gz #解压34cd nginx-1.15.4/35#添加fastdfs-nginx-module模块36./configure --add-module=/usr/local/src/fastdfs-nginx-module/src/ 37make && make install #编译安装38
39# tracker配置40vim /etc/fdfs/tracker.conf41#需要修改的内容如下42port=22122 # tracker服务器端口(默认22122,一般不修改)43base_path=/home/dfs # 存储日志和数据的根目录44
45# storage配置46vim /etc/fdfs/storage.conf47#需要修改的内容如下48port=23000 # storage服务端口(默认23000,一般不修改)49base_path=/home/dfs # 数据和日志文件存储根目录50store_path0=/home/dfs # 第一个存储目录51tracker_server=tracker_server_ip:22122 # tracker服务器IP和端口52http.server_port=8888 # http访问文件的端口(默认8888,看情况修改,和nginx中保持一致)53
54# client测试55vim /etc/fdfs/client.conf56#需要修改的内容如下57base_path=/home/dfs58tracker_server=tracker_server_ip:22122 #tracker服务器IP和端口59
60# 配置nginx访问61vim /etc/fdfs/mod_fastdfs.conf62#需要修改的内容如下63tracker_server=tracker_server_ip:22122 #tracker服务器IP和端口64url_have_group_name=true65store_path0=/home/dfs66#配置nginx.config67vim /usr/local/nginx/conf/nginx.conf68#添加如下配置69server {70 listen 8888; ## 该端口为storage.conf中的http.server_port相同71 server_name localhost;72 location ~/group[0-9]/ {73 ngx_fastdfs_module;74 }75 error_page 500 502 503 504 /50x.html;76 location = /50x.html {77 root html;78 }79}将上述配置好的容器提交为镜像。
4,启动服务
启动容器:
docker container run -it -p 8888:8888 -p 22122:22122 -p 23000:23000 -privileged --name fastdfs-nginx fastdfs-nginx:v1配置路由表:存储服务器在tracker中注册IP地址为容器的虚拟IP地址,当外界通过tracker获得储存服务器的地址时,由于是内部地址导致无法访问存储服务器。通过将请求tracker:22122的数据源地址修改为宿主机地址,当storage的注册请求发送到tracker上时,注册ip就变成宿主机ip,由此tracker在接收查询时也将返回数据集地址,以此保证服务在本地的可见性。
yum install iptables -y;iptables -t nat -A POSTROUTING -p tcp -m tcp --dport 22122 -d tracker_server_ip -j SNAT --to 宿主机IP注意tracker、nginx、storage配置文件中的
tracker_server_ip要设置正确。启动tracker:
fdfs_trackerd /etc/fdfs/tracker.conf启动storage:
fdfs_storaged /etc/fdfs/storage.conf启动nginx:
/usr/local/nginx/sbin/nginx
5,测试
- 测试fastdfs:
fdfs_upload_file /etc/fdfs/client.conf /usr/local/src/nginx-1.15.4.tar.gz - 测试nginx:
http://localhost:8888/XXXX.gz
代理
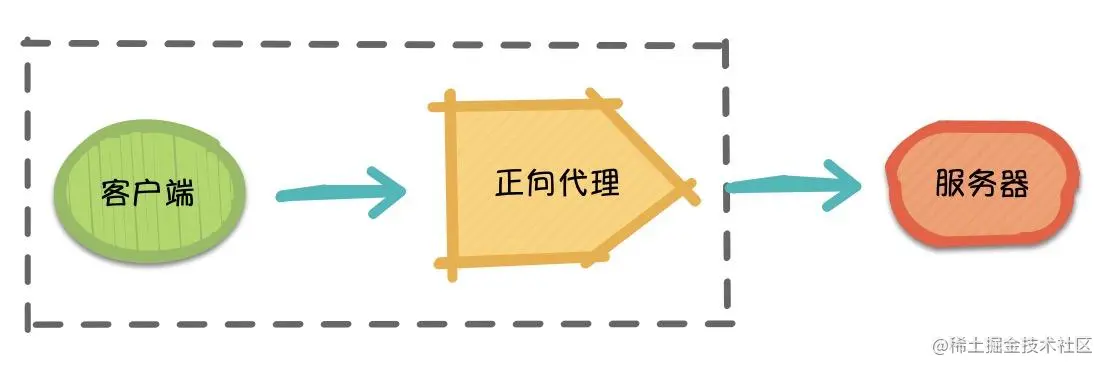
1,正向代理的特点:正向代理是代理客户端,为客户端收发请求,使真实客户端对服务器不可见。服务端不知道客户端、客户端知道服务端,隐藏真实客户端。为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。由于代理对客户端是可感知的,所以必须要进行一些特别的设置才能使用正向代理。 优点:为在防火墙内的局域网客户端提供访问 Internet 的途径。可以做缓存,加速访问资源。对客户端访问授权,上网进行认证。代理可以记录用户访问。记录(上网行为管理),对外隐藏用户信息。
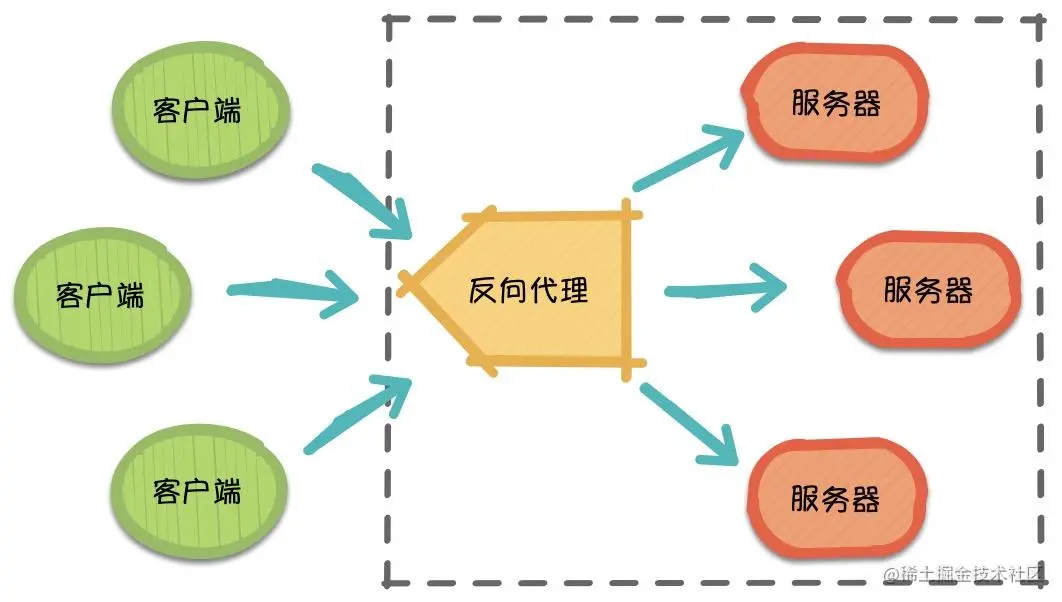
2,反向代理的特点:反向代理是代理服务器端,为服务器收发请求,使真实服务器对客户端不可见。服务端知道客户端、客户端不知道服务端,隐藏真实服务端。客户端请求会先被代理端处理,代理端从另外一台服务器上取回来,然后作为自己的内容吐给用户,客户端对上述流程未知,对于客户端而言代理端就像是原始服务器,并且客户端不需要进行任何特别的设置。
优点:在计算机世界里,由于单个服务器的处理客户端(用户)请求能力有一个极限,当用户的接入请求蜂拥而入时,会造成服务器忙不过来的局面,可以使用多个服务器来共同分担成千上万的用户请求,这些服务器提供相同的服务,对于用户来说,根本感觉不到任何差别。通过将反向代理作为公网访问地址,Web 服务器是内网,由代理端实现请求转发,优化网站的负载,保证内网的安全,隐藏和保护原始服务器。当新加入/移走服务器时,仅仅需要修改负载均衡的服务器列表,而不会影响现有的服务。
Nginx是反向代理服务器。代理其实就是中间人,客户端通过代理发送请求到互联网上的服务器,从而获取想要的资源。实现反向代理、负载均衡。
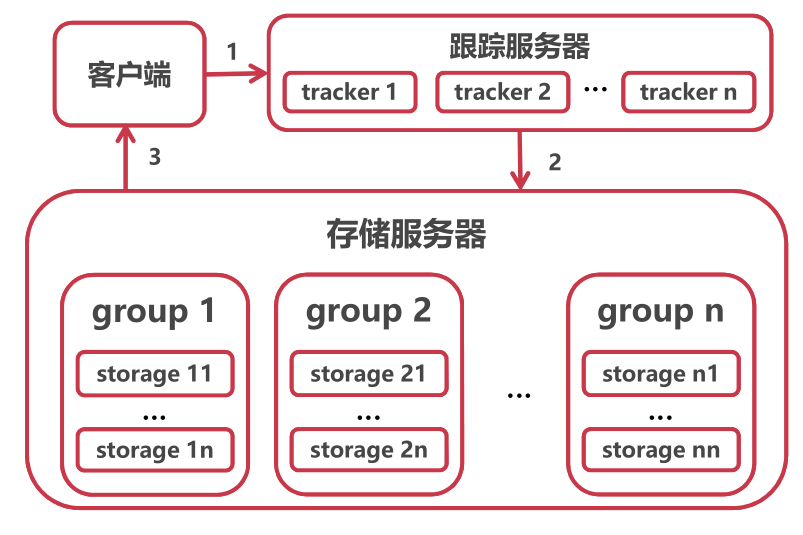
3,fastdfs代理流程:外界访问http://外网IP:8888/group1/MM0/dasfarwfddfd.mp4,其中外网IP:8888为nginx地址,而不是直接访问DFS系统,group1/MM0/dasfarwfddfd.mp4也不在代理端上,nginx从多个tracker选择一个tracker转发请求,实现第一层负载均衡,tracker再从多个group下选择一个group实现第二重负载均衡。

负载均衡
1,内置均衡策略:
轮询(默认):Nginx根据请求次数,将每个请求均匀分配到每台服务器;会话信息丢失:采用ip_hash方式解决,当用户再次访问时,会将该请求通过哈希算法定位到之前登录的服务器(粘滞性会话);复制会话;中心会话保存;基于token的用户认证。缺点:可靠性低和负载分配不均衡。适用于服务器性能相近的集群情况,其中每个服务器承载相同的负载。
xxxxxxxxxx131upstream mybalance01 {2server 172.24.10.22:9090;3server 172.24.10.23:9090;4server 172.24.10.24:9090;5}67server {8listen 80;9server_name balance.linuxds.com;10location / {11proxy_pass http://mybalance01;12}13}weight:加权轮询,加权轮询则是在第一种轮询的基础上对后台的每台服务赋予权重,服务器的权重比例越大,被分发到的概率也就越大。weight和访问比率成正比,用于后端服务器性能不均的情况。会话信息丢失。
xxxxxxxxxx41upstream mybalance01 {2server 172.24.9.11:9090 weight=1 ;3server 172.24.9.12:9090 weight=8 ;4}least_conn:最少连接,将请求分配给连接数最少的服务器。Nginx会统计哪些服务器的连接数最少。
ip_hash:IP 哈希,绑定处理请求的服务器。第一次请求时,根据该客户端的IP算出一个HASH值,将请求分配到集群中的某一台服务器上。后面该客户端的所有请求,都将通过HASH算法,找到之前处理这台客户端请求的服务器,然后将请求交给它来处理。每个访客固定访问一个后端服务器,可以解决session的问题。
xxxxxxxxxx61upstream mybalance01 {2ip_hash;3server 172.24.10.22:9090;4server 172.24.10.23:9090;5server 172.24.10.24:9090;6}
2,扩展均衡策略:
fair:按后端服务器的响应时间来分配请求,响应时间短的优先分配。
url_hash:按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
xxxxxxxxxx71upstream mybalance01 {2hash $request_uri;3hash_method crc32;4server 172.24.10.22:9090;5server 172.24.10.23:9090;6server 172.24.10.24:9090;7}
3,健康检查
如果后端某台服务器响应失败,nginx会标记该台服务器失效,在特定时间内,请求不分发到该台上。
fail_timeout:该指令定义了多长时间服务器将被标记为失败。
max_fails:该指令设置在fail_timeout期间内连续的失败尝试。
xxxxxxxxxx41upstream mybalance01 {2server 172.24.9.11:9090 max_fails=1 fail_timeout=2;3server 172.24.9.12:9090 max_fails=2 fail_timeout=2;4}
分片传输
文件整体传输时,如果文件较大,则会长时间占用网络带宽,挤占其它应用网络;同时当传输被迫中断时,之前传输数据将被丢弃,并从头开始传输。通过对文件分片,按照一定间隔传输分片,不会长时间占据带宽,并且如果传输中断,只会从被中断分片开始传输,之前分片不会重复传输。上传第一个分片时会创建一个新的文件,并返回访问路径,上传后续分片时,路径和偏移量,直接在原始文件的后面添加。分片任务由客户端完成。
xxxxxxxxxx131//上传可以断点续传的文件时的第一个分片,会创建一个新的文件,并访问路径2// 需要指定所在分组,以便后续负载均衡的处理3private String uploadAppenderFile(MultipartFile file) throws Exception {4 String fileType = this.getFileType(file);5 StorePath storePath = appendFileStorageClient.uploadAppenderFile(DEFAULT_GROUP, file.getInputStream(), file.getSize(), fileType);6 return storePath.getPath();7}8
9//上传可以断点续传的文件时的后续分片,根据传入文件分组、路径和偏移量,直接在原始文件的后面添加10private void modifyAppenderFile(MultipartFile file, String filePath, long offset) throws Exception {11 appendFileStorageClient.modifyFile(DEFAULT_GROUP, filePath, file.getInputStream(), file.getSize(), offset);12}13
在对文件分片上传时,需要暂存文件路径和已上传比特数用于将后续分片添加到初始分片文件的尾部,以及当已上传分片数与总分片书相同时,表示数据已传输完成,返回文件路径,每当完成一个分片的传输,都要更新已上传比特数以及已上传分片数。由于这些数据都是临时数据,所以使用redis暂存,key为存储信息种类+文件数值摘要构成,保证唯一性。
xxxxxxxxxx641
2/**3 * 保存分片文件,在所有分片上传完成后返回路径4 *5 * @param [file:分片文件, fileMD5:整个文件摘要, sliceNo:分片编号, totalSliceNo:总分片数]6 * @return java.lang.String7 * @throws8 */9public String uploadFileBySlices(MultipartFile file, String fileMd5, Integer sliceNo, Integer totalSliceNo) throws Exception {10
11 if (file == null || sliceNo == null || totalSliceNo == null) {12 throw new ConditionException("参数异常!");13 }14 // 保存分片文件上传信息,用户后续分片文件的上传15 // 初始分片路径16 String pathKey = PATH_KEY + fileMd5;17 // 已上传大小18 String uploadedSizeKey = UPLOADED_SIZE_KEY + fileMd5;19 // 已上传分片数20 String uploadedNoKey = UPLOADED_NO_KEY + fileMd5;21 // 已上传大小,初始分片为022 String uploadedSizeStr = redisTemplate.opsForValue().get(uploadedSizeKey);23 Long uploadedSize = 0L;24 if (!StringUtil.isNullOrEmpty(uploadedSizeStr)) {25 uploadedSize = Long.valueOf(uploadedSizeStr);26 }27 //上传的是第一个分片,需要在存储服务器上创建文件28 if (sliceNo == 1) {29 String path = this.uploadAppenderFile(file);30 if (StringUtil.isNullOrEmpty(path)) {31 throw new ConditionException("上传失败!");32 }33 // 保存文件路径34 redisTemplate.opsForValue().set(pathKey, path);35 // 保存已上传分片数36 redisTemplate.opsForValue().set(uploadedNoKey, "1");37 } else {38 // 上传的是后续分片,直接存储服务器上文件后面添加数据39 String filePath = redisTemplate.opsForValue().get(pathKey);40 if (StringUtil.isNullOrEmpty(filePath)) {41 throw new ConditionException("上传失败!");42 }43 this.modifyAppenderFile(file, filePath, uploadedSize);44 // 保存已上传分片数45 redisTemplate.opsForValue().increment(uploadedNoKey);46 }47 // 修改历史上传分片文件大小48 uploadedSize += file.getSize();49 redisTemplate.opsForValue().set(uploadedSizeKey, String.valueOf(uploadedSize));50
51 //如果所有分片全部上传完毕,则清空redis里面不再用到的相关的key和value52 String uploadedNoStr = redisTemplate.opsForValue().get(uploadedNoKey);53 Integer uploadedNo = Integer.valueOf(uploadedNoStr);54 String resultPath = "";55 if (uploadedNo.equals(totalSliceNo)) {56 resultPath = redisTemplate.opsForValue().get(pathKey);57 // 删除所有key58 List<String> keyList = Arrays.asList(uploadedNoKey, pathKey, uploadedSizeKey);59 redisTemplate.delete(keyList);60 }61 // 所有分片上传完成后返回路径,否则返回空字符串62 return resultPath;63}64
秒传
对要保存的完整文件生成MD5摘要,MD5摘要之和文件内容相关,与文件名无关,将生成的摘要与已经保存过的文件的摘要进行对比,如果存在匹配项则表示相同文件已经存在,不必重复上传,直接返回已保存文件路径即可,防止保存重复数据。如果不存在相同摘要的文件,则表示是一个新文件,在保存完文件之后一个分片后,将该文件的路径、摘要保存,用于后续文件的摘要比较。
数据表保存文件上传者、路径、md5摘要等信息,由于md5经常被查询,所以建立索引以加快查询速度。
xxxxxxxxxx141-- ----------------------------2-- Table structure for t_file3-- ----------------------------4DROP TABLE IF EXISTS `t_file`;5CREATE TABLE `t_file` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '文件存储路径',8 `type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '文件类型',9 `md5` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '文件md5唯一标识串',10 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',11 PRIMARY KEY (`id`) USING BTREE,12 INDEX userId_index ( `md5`)13
14) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '文件表' ROW_FORMAT = Dynamic;在开始存储分片数据前,先去数据库中查询是否存在与当前完整数字摘要相匹配的数据项,如果存在表示相同文件已保存过,直接返回查询到路径,如果不存在匹配项,则将分片数据保存到FastDFS中,当最后一个分片保存完成后,把文件上传者、路径、md5摘要等信息存入数据库,用于以后秒传时的匹配查找。
xxxxxxxxxx311/**2 * 分片上传文件3 *4 * @param [slice:分片文件, fileMD5:整个文件摘要, sliceNo:分片编号, totalSliceNo:总分片数, userId:用户id]5 * @return java.lang.String6 * @throws7 */8public String uploadFileBySlices(MultipartFile slice, String fileMD5, Integer sliceNo, Integer totalSliceNo) throws Exception {9
10 // 根据文件数值摘要查找完整文件是否已经存在11 DFSFile dbDFSFileMD5 = DFSFileDao.getFileByMD5(fileMD5);12 if (dbDFSFileMD5 != null) {13 // 文件已存在直接返回14 return dbDFSFileMD5.getUrl();15 }16 // 分片上传文件17 String url = fastDFSUtil.uploadFileBySlices(slice, fileMD5, sliceNo, totalSliceNo);18
19
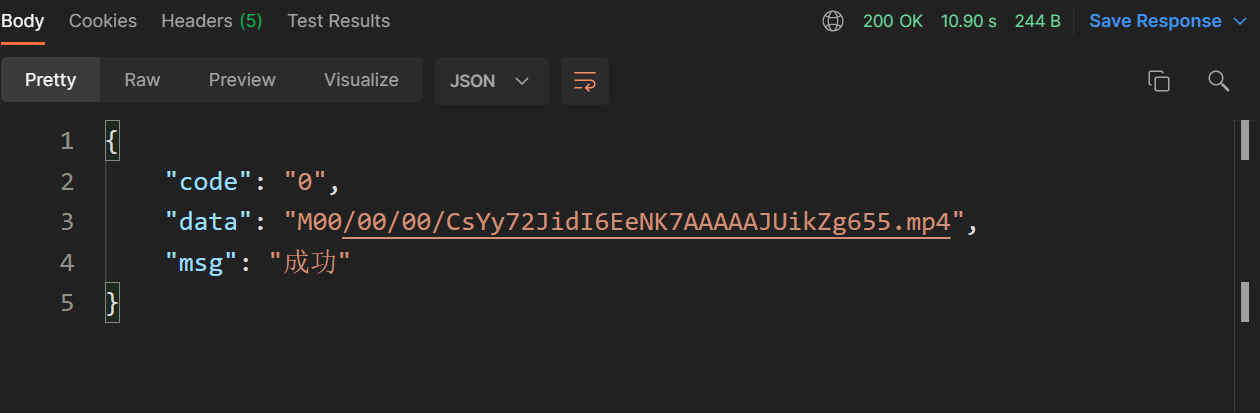
20 // 判断当前分片是否是最后一片21 if (!StringUtil.isNullOrEmpty(url)) {22 // 构建文件信息保存23 dbDFSFileMD5 = new DFSFile();24 dbDFSFileMD5.setCreateTime(new Date());25 dbDFSFileMD5.setMd5(fileMD5);26 dbDFSFileMD5.setUrl(url);27 dbDFSFileMD5.setType(fastDFSUtil.getFileType(slice));28 DFSFileDao.addFile(dbDFSFileMD5);29 }30 return url;31}以上传一个254MB视频为例,分片上传完成后返回文件在存储服务器上的相对地址,耗时10.90S。
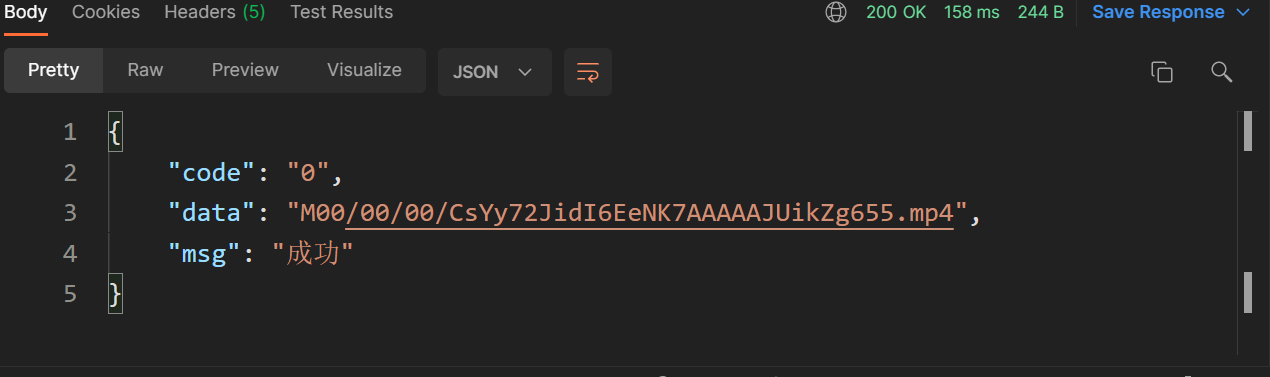
再次上传相同文件时,由于文件md5相同,直接返回该md5对应文件的相对路径,不用上传文件,整个过程耗时158ms。
视频
视频上传
1,数据表设计
t_video视频表存储视频基本信息,包括视频上传者ID、在文件服务器中链接(由文件上传得到)、标题、视频分区(鬼畜、音乐、电影),由于后续会经常对某个用户上传的视频、根据视频标题、视频分区进行查询,所以对userId,title,area建立索引,同时对userId建立外键约束。
xxxxxxxxxx241-- ----------------------------2-- Table structure for t_video3-- ----------------------------4DROP TABLE IF EXISTS `t_video`;5CREATE TABLE `t_video` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `userId` bigint NOT NULL COMMENT '用户id',8 `url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '视频链接',9 `thumbnail` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '封面链接',10 `title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '视频标题',11 `type` varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '视频类型:0原创 1转载',12 `duration` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '视频时长',13 `area` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '所在分区:0鬼畜 1音乐 2电影',14 `description` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL COMMENT '视频简介',15 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',16 `updateTime` datetime NULL DEFAULT NULL COMMENT '更新时间',17 PRIMARY KEY (`id`) USING BTREE,18 INDEX userId_index ( `userId`),19 INDEX title_index ( `title`),20 INDEX area_index ( `area`)21
22) ENGINE = InnoDB AUTO_INCREMENT = 26 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频投稿记录表' ROW_FORMAT = Dynamic;23alter table `t_video` add constraint FK_video_userId foreign key (`userId`) references `t_user`(`id`);24
t_tag表存储视频可选的标签,如二刺螈、老八、孙笑川等。后续可以根据历史观看视频的标签,向用户推送他可能感兴趣的拥有相同标签的视频。由于视频标签类似于公共属性,可以被多用户共享,不想之前的用户关注分组信息那样属于个人独有信息,所以t_tag表不用存储标签的所有者。
xxxxxxxxxx111-- ----------------------------2-- Table structure for t_tag3-- ----------------------------4DROP TABLE IF EXISTS `t_tag`;5CREATE TABLE `t_tag` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '标签名称',8 `createTime` datetime NULL DEFAULT NULL,9 PRIMARY KEY (`id`) USING BTREE10) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '标签表' ROW_FORMAT = Dynamic;11
t_video_tag用于存储视频与标签对应的关系。因为经常需要根据视频ID查询查询视频对应的标签ID,所以建立联合索引(videoId,tagId),直接获取的tagId避免回表,加快查询速度。同时加上外键约束。
xxxxxxxxxx141-- ----------------------------2-- Table structure for t_video_tag3-- ----------------------------4DROP TABLE IF EXISTS `t_video_tag`;5CREATE TABLE `t_video_tag` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `videoId` bigint NOT NULL COMMENT '视频id',8 `tagId` bigint NOT NULL COMMENT '标签id',9 `createTime` datetime NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',10 PRIMARY KEY (`id`) USING BTREE,11 INDEX videoId_tagId_index ( `videoId`,`tagId`)12) ENGINE = InnoDB AUTO_INCREMENT = 32 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频标签关联表' ROW_FORMAT = Dynamic;13alter table `t_video_tag` add constraint FK_video_tag_videoId foreign key (`videoId`) references `t_video`(`id`);14alter table `t_video_tag` add constraint FK_video_tag_tagId foreign key (`tagId`) references `t_tag`(`id`);2,上传
客户端先将文件分片上传到文件服务器,获得文件在存储服务器中路径。然后构建视频Bean包含上传者ID、视频路径、视频分区、视频标签、标签等信息,服务端再保存这些信息。服务端先保存视频信息,再根据回填的视频ID信息,保存频标签信息。
xxxxxxxxxx161// 上传视频2public void addVideos(Video video) {4 // 保存视频,回填视频ID5 Date now = new Date();6 video.setCreateTime(new Date());7 videoDao.addVideos(video);8 // 保存视频标签信息9 Long videoId = video.getId();10 List<VideoTag> tagList = video.getVideoTagList();11 tagList.forEach(item -> {12 item.setCreateTime(now);13 item.setVideoId(videoId);14 });15 videoDao.batchAddVideoTags(tagList);16}查找
根据视频类别查询视频,用于首页的分类别展示。
流程与之前根据昵称分组查询用户相似,先构建分页查询对应的起始位置和每页查询条目数,再查询复合条件的视频条目数,当结果数目大于0时再进行分页查询。
xxxxxxxxxx181public PageResult<Video> pageListVideos(Integer size, Integer no, String area) {2 if (size == null || no == null) {3 throw new ConditionException("参数异常!");4 }5 // 分页查询信息6 Map<String, Object> params = new HashMap<>();7 params.put("start", (no - 1) * size);8 params.put("limit", size);9 params.put("area", area);10 List<Video> list = new ArrayList<>();11 // 查询复合条件的视频数12 Integer total = videoDao.pageCountVideos(params);13 if (total > 0) {14 // 根据调差分页查询用户15 list = videoDao.pageListVideos(params);16 }17 return new PageResult<>(total, list);18}视频播放
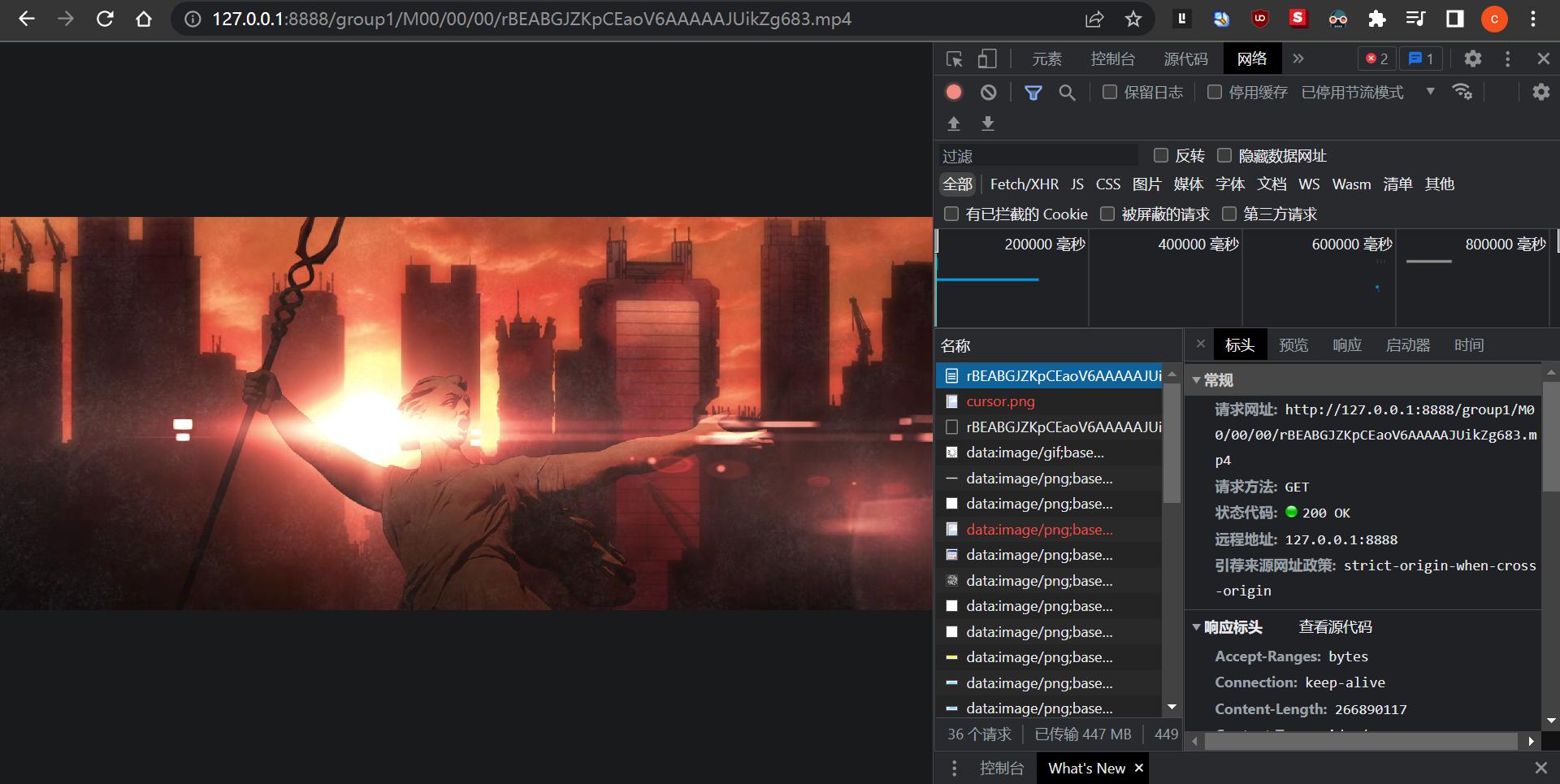
在线播放视频与下载视频相似,在线播放最简单的形式就是直接向客户端发送完整链接地址,其缺点是向外界暴露了文件所处位置http://localhost:8888/group1/M00/00/00/CsYy72JidI6EeNK7AAAAAJUikZg655.mp4,用户可以绕过登录等权限控制,直接访问视频文件,同时如果是在下载场景下,传输终端将导致从头开始传输数据。
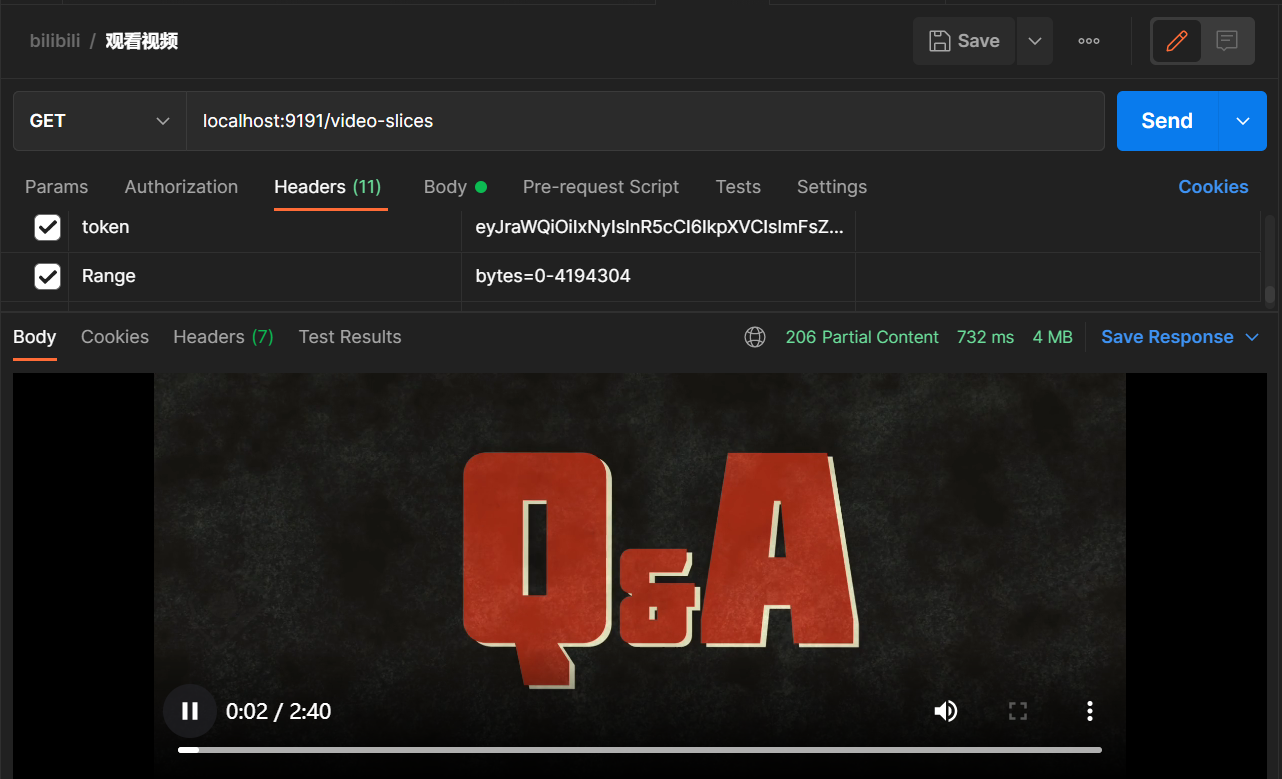
在线播放建议采用分片传输比特流的形式,客户端向服务器发起对某一个分段数据获取请求,http://localhost:9191/video-slices?url=M00/00/00/rBEABGJZKpCEaoV6AAAAAJUikZg683.mp4,其中相对地址指明的视频并不在localhost上(此处演示为单机,处理请求的服务器和文件存储服务器都是本地主机,可以拓展为多机场景),服务端接受请求再去文件存储服务器查找文件,最终以比特流的形式将数据写入http响应,这样外界无法知道文件具体位置,对用户而言数据就保存在localhost,避免文件暴露,同时分片的方式使得断点续传得以实现。
分片请求时客户端通过相对路径指明要获取的视频,并请求头中通过<Range,bytes=start_byte-end_byte>,指明当前分片请求的开始和结束比特数。服务端通过对存储服务器地址和文件相对路径的拼接获得完整路径,并从存储服务器中读取指定比特数,写入http响应。同时向响应头中写入数据,对返回的比特流进行说明描述:<Content-Range, "bytes+start_byte-end_byte+/+total_size> ,<Accept-Ranges, bytes>,<Content-Type, video/mp4>,设置内容长度为分片长度,响应码为HttpServletResponse.SC_PARTIAL_CONTENT表示返回部分内容。
xxxxxxxxxx511 /**2 * 分片返回视频比特流数据3 *4 * @param request, response, path5 * @return void6 * @throws7 */8public void viewVideoOnlineBySlices(HttpServletRequest request,HttpServletResponse response,String path) throws Exception {9 // 获得文件基本信息10 FileInfo fileInfo = fastFileStorageClient.queryFileInfo(DEFAULT_GROUP, path);11 long totalFileSize = fileInfo.getFileSize();12 // path为相对路径,格式为: M00/00/00/rBEABGJZI3GAeeQOAA-itrfn0m4.tar.gz13 // 需要补全存储服务器的ip,端口,以及文件所在group,最终获得完整地址14 String url = httpFdfsStorageAddr + path;15 //获取请求头信息16 Enumeration<String> headerNames = request.getHeaderNames();17 Map<String, Object> headers = new HashMap<>();18 while (headerNames.hasMoreElements()) {19 String header = headerNames.nextElement();20 headers.put(header, request.getHeader(header));21 }22 // 获得请求的比特范围23 String rangeStr = request.getHeader("Range");24 String[] range;25 if (StringUtil.isNullOrEmpty(rangeStr)) {26 // 未指定直接返回完整比特27 rangeStr = "bytes=0-" + (totalFileSize - 1);28 }29 // [,start],[,start,end]30 // 获取起始比特31 range = rangeStr.split("bytes=|-");32 long begin = 0;33 if (range.length >= 2) {34 begin = Long.parseLong(range[1]);35 }36 // 获取终止比特37 long end = totalFileSize - 1;38 if (range.length >= 3) {39 end = Long.parseLong(range[2]);40 }41 long len = (end - begin) + 1;42 // 分片传输时设置响应头43 String contentRange = "bytes " + begin + "-" + end + "/" + totalFileSize;44 response.setHeader("Content-Range", contentRange);45 response.setHeader("Accept-Ranges", "bytes");46 response.setHeader("Content-Type", "video/mp4");47 response.setContentLength((int) len);48 response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);49 // 读取文件并写入http响应50 HttpUtil.get(url, headers, response);51}读取文件流时先构建http连接,前客户端请求头参数填入,从与文件储存服务器建立的连接获得输出流,读取数据从将要返回的响应获取输出流,写入数据,完成文件比特流的传输。
xxxxxxxxxx411/**2 * http get请求 返回输出流,可以配置请求头3 *4 * @param url 请求链接5 * @param headers 请求头6 * @param response 响应7 */8public static OutputStream get(String url,Map<String, Object> headers,HttpServletResponse response) throws Exception {9 // 打开链接10 URL urlObj = new URL(url);11 HttpURLConnection con = (HttpURLConnection) urlObj.openConnection();12 con.setDoInput(true);13 con.setRequestMethod(REQUEST_METHOD_GET);14 con.setConnectTimeout(CONNECT_TIME_OUT);15 // 设置请求参数16 for (Entry<String, Object> entry : headers.entrySet()) {17 String key = entry.getKey();18 String value = String.valueOf(entry.getValue());19 con.setRequestProperty(key, value);20 }21 con.connect();22 // 读取输出流23 BufferedInputStream bis = new BufferedInputStream(con.getInputStream());24 OutputStream os = response.getOutputStream();25 // 响应码26 int responseCode = con.getResponseCode();27 byte[] buffer = new byte[1024];28 // 响应码[200,300)表示读取正常29 if (responseCode >= 200 && responseCode < 300) {30 // 从文件输入流读取,下入http相应的输出流31 int i = bis.read(buffer);32 while ((i != -1)) {33 os.write(buffer, 0, i);34 i = bis.read(buffer);35 }36 bis.close();37 }38 bis.close();39 con.disconnect();40 return os;41}分片播放效果如下:
点赞
t_video_like保存用户的点赞记录,关联用户ID与被点赞的视频的ID,由于需要查询某个用户点赞了哪些视频,索引建立联合索引(userId,videoId),避免回表,加快查询数据。
xxxxxxxxxx151-- ----------------------------2-- Table structure for t_video_like3-- ----------------------------4DROP TABLE IF EXISTS `t_video_like`;5CREATE TABLE `t_video_like` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `userId` bigint NOT NULL COMMENT '用户id',8 `videoId` bigint NOT NULL COMMENT '视频投稿id',9 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',10 PRIMARY KEY (`id`) USING BTREE,11 INDEX userId_videoId_index ( `userId`,`videoId`)12) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频点赞记录表' ROW_FORMAT = Dynamic;13alter table `t_video_like` add constraint FK_video_like_userId foreign key (`userId`) references `t_user`(`id`);14alter table `t_video_like` add constraint FK_video_like_videoId foreign key (`videoId`) references `t_video`(`id`);15
客户端传递要点赞的视频ID,后端一次验证视频ID是否合法,用户是否已经点赞过该视频,通过后往`t_video_like添加点赞记录。
xxxxxxxxxx191// 添加点赞记录2public void addVideoLike(Long videoId, Long userId) {3 // 视频ID验证4 Video video = videoDao.getVideoById(videoId);5 if (video == null) {6 throw new ConditionException("非法视频!");7 }8 // 该用户是否已经点赞过该视频9 VideoLike videoLike = videoDao.getVideoLikeByVideoIdAndUserId(videoId, userId);10 if (videoLike != null) {11 throw new ConditionException("已经赞过!");12 }13 // 添加点赞记录14 videoLike = new VideoLike();15 videoLike.setVideoId(videoId);16 videoLike.setUserId(userId);17 videoLike.setCreateTime(new Date());18 videoDao.addVideoLike(videoLike);19}取消点赞、查看视频被点赞数、查看用户点赞过的视频依据数据表实现即可,不再赘述。
投币
1,数据表设计
t_video_coin 保存用户视频投币记录,包含用户ID,视频ID,投币数。由于经常查询某用户投币了哪些视频,所以建立联合索引( userId,videoId),避免回表加快查询。由于一行记录包含两个其它表的主键,所以对userId、videoId添加外键约束。t_user_coin保存用户的硬币账户余额,由于经常查询某用户的账户余额,所以建立联合索引( userId,amount),避免回表加快查询,同时对userId添加外键约束。
xxxxxxxxxx301-- ----------------------------2-- Table structure for t_video_coin3-- ----------------------------4DROP TABLE IF EXISTS `t_video_coin`;5CREATE TABLE `t_video_coin` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID'7 `userId` bigint NULL DEFAULT NULL COMMENT '用户id',8 `videoId` bigint NULL DEFAULT NULL COMMENT '视频投稿id',9 `amount` int NULL DEFAULT NULL COMMENT '投币数',10 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',11 `updateTime` datetime NULL DEFAULT NULL COMMENT '更新时间',12 PRIMARY KEY (`id`) USING BTREE,13 INDEX userId_videoId_index ( `userId`,`videoId`)14) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频硬币表' ROW_FORMAT = Dynamic;15alter table `t_video_coin` add constraint FK_video_coin_videoId foreign key (`videoId`) references `t_video`(`id`);16alter table `t_video_coin` add constraint FK_video_coin_userId foreign key (`userId`) references `t_user`(`id`);17
18-- ----------------------------19-- Table structure for t_user_coin20-- ----------------------------21CREATE TABLE `t_user_coin`(22 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',23 `userId` bigint DEFAULT NULL COMMENT '用户id',24 `amount` bigint DEFAULT NULL COMMENT '硬币总数' ,25 `createTime` datetime DEFAULT NULL COMMENT '创建时间' ,26 `updateTime` datetime DEFAULT NULL COMMENT '更新时间' ,27 PRIMARY KEY (`id`) USING BTREE,28 INDEX userId_amount_index ( `userId`,`amount`)29)ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='用户';30alter table `t_user_coin` add constraint FK_user_coin_userId foreign key (`userId`) references `t_user`(`id`);每个用于对一个视频最多投两枚硬币,可以一次投两枚,也可以分两次投。投币时先检查余额是否充足,并保证当前投币完成后,该用户对该视频投币总数小于等于2,更新投币记录条目,最后更新账户余额。
xxxxxxxxxx441// 视频投币2public void addVideoCoins(VideoCoin videoCoin, Long userId) {4 // 参数检验5 Long videoId = videoCoin.getVideoId();6 Integer amount = videoCoin.getAmount();7 if (videoId == null) {8 throw new ConditionException("参数异常!");9 }10 Video video = videoDao.getVideoById(videoId);11 if (video == null) {12 throw new ConditionException("非法视频!");13 }14 //查询当前登录用户是否拥有足够的硬币15 Integer userCoinsAmount = userCoinService.getUserCoinsAmount(userId);16 userCoinsAmount = userCoinsAmount == null ? 0 : userCoinsAmount;17 if (amount > userCoinsAmount) {18 throw new ConditionException("硬币数量不足!");19 }20 //查询当前登录用户对该视频已经投了多少硬币21 VideoCoin dbVideoCoin = videoDao.getVideoCoinByVideoIdAndUserId(videoId, userId);22 //新增视频投币23 if (dbVideoCoin == null) {24 if (amount > 2) {25 throw new ConditionException("最多只能投两枚硬币");26 }27 videoCoin.setUserId(userId);28 videoCoin.setCreateTime(new Date());29 videoDao.addVideoCoin(videoCoin);30 } else {31 Integer dbAmount = dbVideoCoin.getAmount();32 dbAmount += amount;33 if (dbAmount > 2) {34 throw new ConditionException("总共可以投两枚硬币");35 }36 //更新视频投币37 videoCoin.setUserId(userId);38 videoCoin.setAmount(dbAmount);39 videoCoin.setUpdateTime(new Date());40 videoDao.updateVideoCoin(videoCoin);41 }42 //更新用户当前硬币总数43 userCoinService.updateUserCoinsAmount(userId, (userCoinsAmount - amount));44}查看视频被投币总数、查看用户投币过的视频依据数据表实现即可,不再赘述。
收藏
1,数据表设计
t_collection_group保存用户建立的收藏分组,由于收藏分组为用户私有,需要将分组信息与用户关联,同时默认分组为用户共享,预先插入一条不予用户关联的默认分组。同时对 userId建立索引与外键约束。

t_video_collection保存收藏记录,包括用户ID、被收藏视频ID和收藏分组,由于经常查询某用户收藏视频,所以建立联合索引( userId,videoId),避免回表加快查询。由于一行记录包含三个其它表的主键,所以对groupId、userId、videoId添加外键约束。
xxxxxxxxxx321-- ----------------------------2-- Table structure for t_collection_group3-- ----------------------------4DROP TABLE IF EXISTS `t_collection_group`;5CREATE TABLE `t_collection_group` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `userId` bigint NULL DEFAULT NULL COMMENT '用户id',8 `name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '关注分组名称',9 `type` varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '关注分组类型:0默认分组 1用户自定义分组',10 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',11 `updateTime` datetime NULL DEFAULT NULL COMMENT '更新时间',12 PRIMARY KEY (`id`) USING BTREE,13 INDEX userId_index ( `userId`)14) ENGINE = InnoDB AUTO_INCREMENT = 16 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '收藏分组表' ROW_FORMAT = Dynamic;15alter table `t_collection_group` add constraint FK_collection_group_userId foreign key (`userId`) references `t_user`(`id`);16
17-- ----------------------------18-- Table structure for t_video_collection19-- ----------------------------20DROP TABLE IF EXISTS `t_video_collection`;21CREATE TABLE `t_video_collection` (22 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',23 `videoId` bigint NULL DEFAULT NULL COMMENT '视频投稿id',24 `userId` bigint NULL DEFAULT NULL COMMENT '用户id',25 `groupId` bigint NULL DEFAULT NULL COMMENT '收藏分组id',26 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',27 PRIMARY KEY (`id`) USING BTREE,28 INDEX userId_videoId_index ( `userId`,`videoId`)29) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频收藏记录表' ROW_FORMAT = Dynamic;30alter table `t_video_collection` add constraint FK_video_collection_videoId foreign key (`videoId`) references `t_video`(`id`);31alter table `t_video_collection` add constraint FK_video_collection_userId foreign key (`userId`) references `t_user`(`id`);32alter table `t_video_collection` add constraint FK_video_collection_groupId foreign key (`groupId`) references `t_collection_group`(`id`);添加收藏、删除收藏、查询收藏过视频等功能频依据数据表实现即可,不再赘述。
评论
1,数据表设计
t_video_comment存储评论信息。包括被评论视频ID、发表评论的用户ID、评论本身、本条评论回复的用户、以及评论所在评论组的根评论对应的用户,由于设计到多个表的主键,所以对userId和videoId添加外键约束。多用户回复是一个嵌套的树形结构,B站为简化存储使用两次存储结构,第一级为根评论,第二季为由根评论衍生的评论。
比如视频下初始评论A,之后用户回复了评论A,得到评论B,之后用户回复了评论B,得到评论C。
xxxxxxxxxx71A--2 |3 B--4 | |5 D C--6 |7 E对于评论A,由于是最顶层评论,所以replyUserId、rootId都为空;对于评论B,由于是第二层评论,所以replyUserId、rootId都为A对应用户;对于评论C,由于是第三层评论,所以replyUserId为B对应用户、rootId为A对应用户。
xxxxxxxxxx171-- ----------------------------2-- Table structure for t_video_comment3-- ----------------------------4DROP TABLE IF EXISTS `t_video_comment`;5CREATE TABLE `t_video_comment` (6 `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',7 `videoId` bigint NOT NULL COMMENT '视频id',8 `userId` bigint NOT NULL COMMENT '用户id',9 `comment` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '评论',10 `replyUserId` bigint NULL DEFAULT NULL COMMENT '回复用户id',11 `rootId` bigint NULL DEFAULT NULL COMMENT '根节点评论id',12 `createTime` datetime NULL DEFAULT NULL COMMENT '创建时间',13 `updateTime` datetime NULL DEFAULT NULL COMMENT '更新时间',14 PRIMARY KEY (`id`) USING BTREE15) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '视频评论表' ROW_FORMAT = Dynamic;16alter table `t_video_comment` add constraint FK_video_comment_videoId foreign key (`videoId`) references `t_video`(`id`);17alter table `t_video_comment` add constraint FK_video_comment_userId foreign key (`userId`) references `t_user`(`id`);2,分页查询评论
由于使用两级存储体系,返回给前端数据需要以根评论为单位,每个根评论内部保存其对应的子评论,根评论本身保存:评论文本、发表评论的用户信息、被评论视频ID,子评论除了根评论保存的信息,还包含回复的用户的信息和根评论ID。
xxxxxxxxxx631 /**2 * 分页查询视频评论,返回一个根评论的列表,每个根评论保存其对应子评论的信息。3 *4 * @param size:分页大小5 * @param no:第几页6 * @param videoId:视频ID7 * @return8 */9public PageResult<VideoComment> pageListVideoComments(Integer size, Integer no, Long videoId) {10 // 参数校验11 Video video = videoDao.getVideoById(videoId);12 if (video == null) {13 throw new ConditionException("非法视频!");14 }15 // 分页信息16 Map<String, Object> params = new HashMap<>();17 params.put("start", (no - 1) * size);18 params.put("limit", size);19 params.put("videoId", videoId);20 // 当前视频根评论数(root=null)21 Integer rootCommitTotal = videoDao.pageCountVideoComments(params);22 // 当前视频根评论(root=null)23 List<VideoComment> rootCommitList = new ArrayList<>();24 if (rootCommitTotal > 0) {25 rootCommitList = videoDao.pageListVideoComments(params);26 // 根评论ID27 List<Long> rootCommitIdList = rootCommitList.stream().map(VideoComment::getId).collect(Collectors.toList());28 // 查询各个根评论下子评论29 List<VideoComment> childCommentList = videoDao.batchGetVideoCommentsByRootIds(rootCommitIdList);30 // 批量查询根评论对应用户信息31 Set<Long> commitUserIdList = rootCommitList.stream().map(VideoComment::getUserId).collect(Collectors.toSet());32 // 获得子评论回复的对象的ID33 Set<Long> replyUserIdList = childCommentList.stream().map(VideoComment::getReplyUserId).collect(Collectors.toSet());34 // 初始commitUserIdList和replyUserIdList存在重复,使用set去重35 // 获得全部评论对应的用户ID36 commitUserIdList.addAll(replyUserIdList);37 // 获得全部评论对应的用户信息38 List<UserInfo> userInfoList = userService.batchGetUserInfoByUserIds(commitUserIdList);39 // 构建<userId,userInfo>键值对,方便后续匹配40 Map<Long, UserInfo> userInfoMap = userInfoList.stream().collect(Collectors.toMap(UserInfo::getUserId, userInfo -> userInfo));41 rootCommitList.forEach(comment -> {42 // 根评论ID43 Long id = comment.getId();44 // 当前根评论对应的子评论集合45 List<VideoComment> childList = new ArrayList<>();46 childCommentList.forEach(child -> {47 // 找到当前根评论对应的子评论48 if (id.equals(child.getRootId())) {49 // 设置子评论对应的用户信息50 child.setUserInfo(userInfoMap.get(child.getUserId()));51 // 设置子评论所回复用户对应的用户信息52 child.setReplyUserInfo(userInfoMap.get(child.getReplyUserInfo()));53 childList.add(child);54 }55 });56 // 设定根评论对应的子评论列表57 comment.setChildList(childList);58 // 设置根评论自身对应的用户信息59 comment.setUserInfo(userInfoMap.get(comment.getUserId()));60 });61 }62 return new PageResult<>(rootCommitTotal, rootCommitList);63}获取视频信息
视频信息包含:视频标题、上传时间、分区、标签、简介、在存储服务器上的相对路径,以上信息由Video封装;点赞数、投币数、收藏数,需要到数据库中查询;视频上传者信息使用UserInfo封装。
xxxxxxxxxx361/**2 * 获取视频详情,包括视频信息、上传用户信息、点赞、收藏、投币3 *4 * @param videoId5 * @return6 */7public Map<String, Object> getVideoDetails(Long videoId, Long userId) {8 // 获得视频信息9 Video video = videoDao.getVideoDetails(videoId);10 // 获得上传者信息11 Long upUserId = video.getUserId();12 User user = userService.getUserInfo(upUserId);13 UserInfo userInfo = user.getUserInfo();14 // 获得点赞信息15 Map<String, Object> likeResult = getVideoLikes(videoId, userId);16 // 获得投币信息17 Map<String, Object> coinResult = getVideoCoins(videoId, userId);18 // 获得收藏信息19 Map<String, Object> collectionResult = getVideoCollections(videoId, userId);20 Map<String, Object> result = new HashMap<>();21 result.put("video", video);22 result.put("upUserInfo", userInfo);23 // 点赞总数24 result.put("likeCount", likeResult.get("count"));25 // 当前用户是否点赞26 result.put("isLike", likeResult.get("like"));27 // 投币总数28 result.put("coinCount", coinResult.get("count"));29 // 当前用户投币数30 result.put("isCoin", coinResult.get("coined"));31 // 收藏总数32 result.put("collectCount", collectionResult.get("count"));33 // 当前用户是否收藏34 result.put("isCollect", collectionResult.get("collect"));35 return result;36}返回给前端信息如下:
xxxxxxxxxx361{2 "coinCount": 0, #投币数3 "collectCount": 0, #收藏数 4 "isCoin": 0,# 当前用户是否已投币5 "isCollect": false,# 当前用户是否已收藏6 "isLike": false,# 当前用户是否已点赞7 "likeCount": 0, #点赞数数 8 # up主信息9 "upUserInfo": {10 "avatar": "",11 "birth": "1999-10-01",12 "createTime": "2022-04-11 15:34:58",13 "followed": null,14 "gender": "0",15 "id": 10,16 "nick": "萌新",17 "sign": "",18 "updateTime": null,19 "userId": 17 # 用户ID20 },21 # 视频信息22 "video": {23 "area": "0",# 分区24 "createTime": "2022-04-16 12:44:27",# 上传时间25 "description": "wrewe",# 描述26 "duration": "111",# 视频时长27 "id": 33,#视频ID28 "thumbnail": "thumbnail",29 "title": "前进4Eva",# 视频标题30 "type": "0",# 视频类型31 "updateTime": null,32 "url": "M00/00/00/rBEABGJZKpCEaoV6AAAAAJUikZg683.mp4",# 在文件存储服务器中相对位置33 "userId": 17,# 上传者ID34 "videoTagList": []# 视频标签35 }36}